浅谈搜索推荐技术在电商导购领域的应用
应用一:分词

作者:高扬
在电商领域浸淫多年,近期有空对这些年的实践经历做些整理,唠叨唠叨我们遇到的问题和用到的技术解决方案,欢迎同行交流。
PS:封面图跟本文没有任何卵关系,纯粹个人喜欢……
导购领域的发展
随着经济不断发展,人们对消费品质要求也水涨船高,也更加个性化。线下实体的陈列空间是有限的,网上陈列空间是无限的,所以这十多年来,电子商务一直处于蓬勃发展之中。
海量商品,虽然极大丰富了的选择,但也让你挑花了眼,经常会被坑爹……所以,这就有了导购的生存土壤。导购,故名思议,引导购物,本质上是一个信息过滤器,针对个人的需求和喜好,将海量商品过滤成有限选择,减轻挑选成本。
如果把网上商品库比喻成一个西瓜,导购就是切西瓜的刀,一个特定的角度切入,就是一个导购方向。举个栗子:
早期的购物搜索、购物推荐是最早的导购形态,让用户自助寻找想买的商品;
折800,聚划算,9块9包邮,什么值得买等,是以价格角度切入;
美丽说、蘑菇街是以女性时尚角度切入;
chiphell,knewone是以男性原创晒单角度切入……
只要网上的商品信息保持持续增长,信息过滤、商品挑选的用户痛点也会日益增加,导购需求就会永远存在。
个性精准导购,对技术要求较高,需要用到搜索,推荐,机器学习等多个领域技术。
导购离钱近,可很快有现金流,属于“自我造血型”业务,在这个资本寒冬里,是一个不错的选择。
做好导购,未来可演化成垂直电商平台,发展前景广阔,美丽说、蘑菇街是成功案例。
说那么多废话,我就是想简单讲一下分词
为了有效的给用户推荐商品,首先要理解用户需求和商品,这两者的精准刻画都离不开分词。
我们这里说的分词是指中文分词,指的是将一个汉字序列切分成一个一个单独的词。这是中文特有的问题(英文有空格可以天然分隔),需要进行一些技术处理。
通用的分词算法可分三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。这里不展开详述,大家可以自行百度,这三个分词流派我们都用上了。
在实践过程会发现,无论哪种方法,都保证不了100%的召回率和准确率,技术同学通常面临这样一个难题:召回率83%,准确率91%,想进一步提高准确率,就很难保持召回率不降低,怎么破?!
这时候,你需要词典了。
购物分词优化到后期,基本就是词典的优化过程。
词典是一个扩展集合,用于保存预先分好的词,每一个词要标注词性。词性,就是词的性质,是对一个词的进一步解释,比如“D100”在词性是“系列”,“尼康”的词性是“品牌”。(词条,词性)组合,可以保存对应的领域知识。
再列举一些我们用到的词性
核心词:如品牌,型号,系列,商品名等
修饰词:如颜色,材质,风格等
Stopword:无意义的词,如包邮,淘宝热卖等
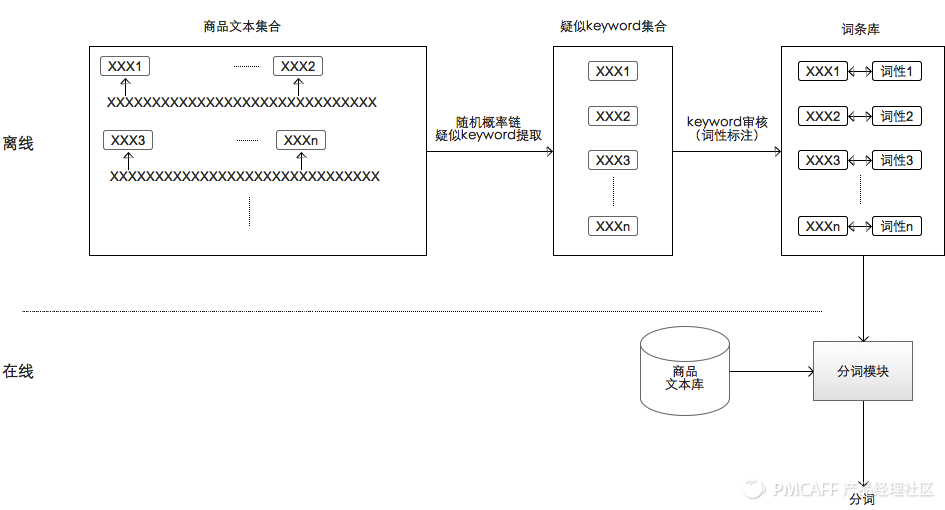
我们词典的最大特点是基于分类的,也就是说,词典中每一个词的词性并不是唯一性确定的,在不同类目下有不同的词性含义。目前我们维护的电商分类是数千个节点,深度为4的树形结构,常见的分类有手机,连衣裙,膨化食品……

这是我们一个词条的印象,大家感觉一下。
下面是我们设计的词条数据结构。
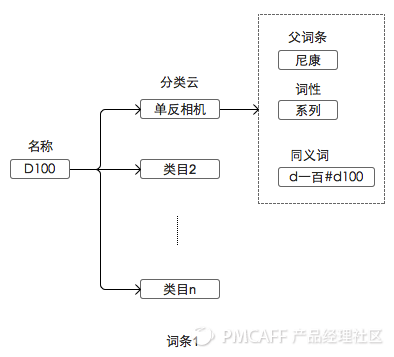
我们词条的词性是基于分类的。
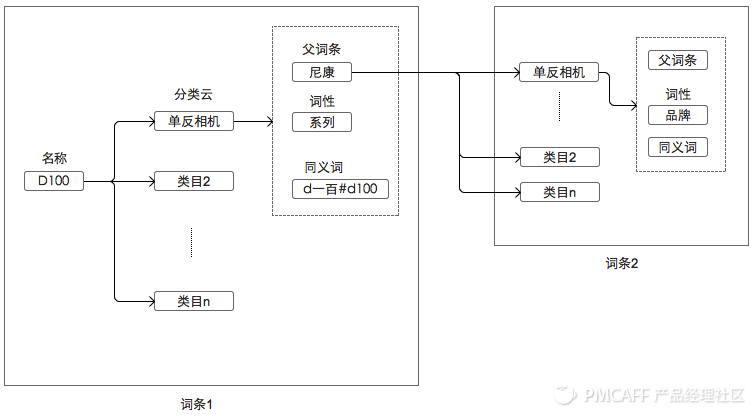
词条的组织形式是分形的,可递归,父词条结构和词条是一样的。
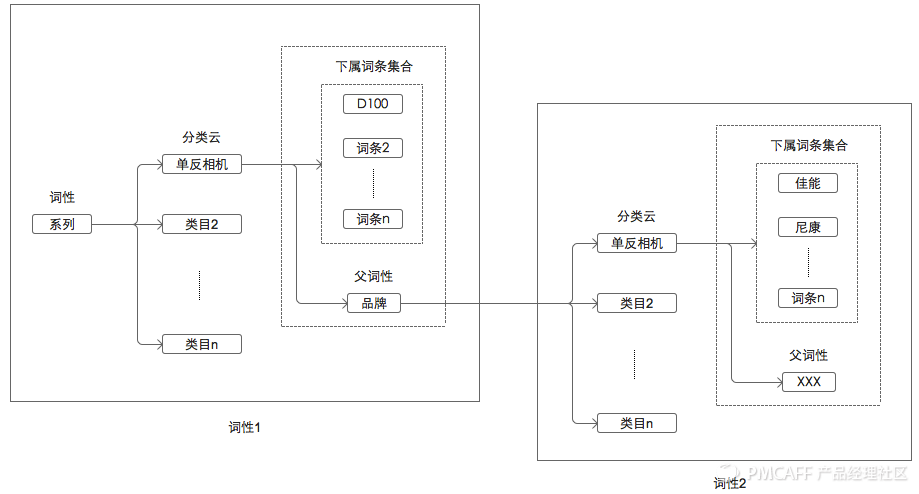
这是词性维度的数据结构,也是基于分类的。
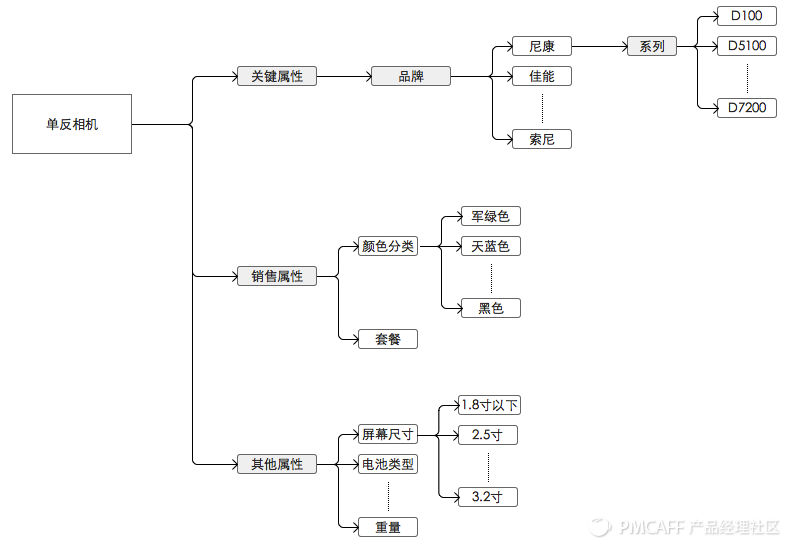
最终,我们通过词条关系的构建,搭建成如上类目属性库,在各种商品文本处理场景中使用。
那么问题来了,那么多品牌词,类目词,修饰词都是从哪里来的呢?
答:从大数据里面来。
通过海量商品文本数据,我们对文本中,相邻的keyword建立起概率链模型,如果两个keyword经常一起出现,同时词条库里面还没有,那很可能是一个新词。这时候,人工介入标注,更新词条库。日积月累,词条库会越来越强大!
最后,我们的购物分词系统,就演化成介个酱紫的。
应用二:爬虫

文/高扬
什么是爬虫?
爬虫只是一种形象的比喻,不是树上爬来爬去的那种……爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分,是数据处理的第一个环节。大体上,可以有传统和垂直两种类型,传统的就是google、baidu大搜索爬虫,本篇介绍是的电商垂直爬虫。
做一个简单的爬虫很容易,你只要写下面这行代码:
wget http://www.meituan.com/
完了……
看,很简单吧,大家都觉得写一个爬虫很简单,也预示着爬虫攻城湿苦逼日子的开始……
上面这行代码给学生讲讲课是够用的,但实战还需要解决很多问题,爬虫的基本工作有抓取、抽取、存储,我们分别说一说。
(一)抓取
1. 编码识别&翻页
互联网上的网页大多是http协议的,但编码每家都不一样,有utf-8,gbk,gb2312等等。如果无视编码问题,会使部分网页下载后是乱码,导致无法使用。
通常网页head标签内会标记编码,例如 ,但总有不靠谱的网站维护者不遵守标准,实际编码并不一定是utf8的。我们研发了一种通用技术解决方案:编码智能识别。我们内置了每个编码的常用字符集二进制码,然后将网页内容二进制化,找出匹配度最大的,作为这个网页的真正编码。这个方法很有效,99%+的准确率,就是稍微耗费点CPU,我们基本都用这个方法来识别网页编码,无视charset标签。
,但总有不靠谱的网站维护者不遵守标准,实际编码并不一定是utf8的。我们研发了一种通用技术解决方案:编码智能识别。我们内置了每个编码的常用字符集二进制码,然后将网页内容二进制化,找出匹配度最大的,作为这个网页的真正编码。这个方法很有效,99%+的准确率,就是稍微耗费点CPU,我们基本都用这个方法来识别网页编码,无视charset标签。
另外,很多电商商品页面,部分区域是ajax异步加载的,用POST的也比较多,直接使用wget、curl有诸多不便,需要支持。我们对其进行了整体封装,内部称这个类库为httpfetcher。
2. 智能的调度、更新
电商网页变化比较频繁,特别是商品价格字段,有时候几乎几分钟一变。上亿的商品库做到每个商品都能及时更新是很困难的,如何用有限资源,抓取最应该更新的商品,是一个难题。以商品更新为例,我们采用基于卖场场景的调度方式,不同的卖场场景更新频率不同,每一个爬虫负责特定场景的抓取任务,称作一个环。发现环负责粗粒度发现,更新环负责粗粒度更新,秒杀环负责限时抢购类的细粒度更新,如下图

3. 重复抓取规避
带宽,恩,带宽……一谈到带宽,爬虫湿都双眉紧锁。创业小公司,不是BAT那种不差钱的主,在北京这种地方带宽是很贵滴,如果能省下一点点带宽,那年终奖都出来了滴。gzip压缩这种优化标准套餐后,我们还需要解决重复网页抓取,节约带宽。
我们管理的网址是亿级别的,普通hashmap在内存中存不下,需要使用Bloom Filter了。
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。

在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素。y2或者属于这个集合,或者刚好是一个false positive。

Bloom Filter的这种高效是有一定代价:
1. 在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。不过对于爬虫场景,来判断一个网址是否被抓取过来说,这种误判率是可以接受的。
2. 无法unset。如果一个网页较早前被抓取过,因为某种原因想再抓一次,Bloom Filter下无法重新清状态再抓取。我们在实践中,采用的是定期清空Bloom Filter,在带宽浪费和unset之间做了一个平衡。
此外,抓取还要解决防封禁等。
(二)抽取
垂直爬虫所涉及的网页空间相对比较集中,对数据结构化要求较高,需要通过模板来解决。我们定义并使用了四种模板:URL模板,列表模板,商品模板和点评模板,这里简单说说前三种。
URL模板
1. URL归一化
商品URL可以标识一个唯一商品,在网站上同一个商品可能有不同的url,原因可能多方面的,一是入口不一样,列表页,搜索页点击过去的页面是不一样的,二是URL后面经常带有统计信息。这样会导致库里大量的商品重复以及Bloom Filter失效,所以需要采用某种规则,将这些URL转化为同一类型的URL,被我们成为URL归一化。
2. URL特征
制定不同的规则来判定是列表url还是商品url,方便采取不同的抓取策略。列举一些URL模板例子:
商品URL模板
www.jd.com|^/product/[0-9]+\.html.*$
book.jd.com|^/[0-9]+\.html.*$
列表模板
表明当前的为一个列表模板,需要通过模板获取的信息为商品总页数
一个列表链接意味着这个链接上面都是一个跳出的链接,通过获取所有的链接,然后与当前网站商品的URL特征匹配,可以获得纯净的商品URL链接,从而控制了发现的链接的准确性。
当一个页面可以翻页的时候,种子URL模板如下
http://www.jd.com/products/652-828-1107-0-0-0-0-0-0-0-1-5-[xx].html
爬虫收到这种类型的链接,按照初始默认起始页,步长爬起第一个页面。
http://www.jd.com/products/652-828-1107-0-0-0-0-0-0-0-1-5-1.html。爬取完毕以后,通过列表模板获得商品总页数,写入到链接对象持久化。然后将这个链接新发现的商品链接和自身写入URLDB。当爬虫在次从URLDB取到这个链接时,发现这个链接是可以翻页的连接,于是按照当前的pageIndex,pageStep计算出下一个页面。然后爬取下一个页面。
商品模板
早期商品模板主要使用Xpath正则、JS子模板及自定义的表达式来完成商品信息的解析。Xpath正则很常见,自行百度。JS子模板主要用来解决一些技术的问题
1,实现在解析某个页面时调用其子页面(ajax),因为有时某些商品信息(如点评量),在商品页的html代码中是不存在的,需要调用该商品页的子页面(如点评页)才能获取;
2,实现从页面中抽取内容传递给某个中间变量(虚拟的模板项),因为有时某个最终结果需要同时对两个中间结果做处理才能得到,需要支持创建多个中间变量。
JS子模板这个名字不好,最初未来解决javascript带来的问题,后面也就懒得改了。随着技术的迭代优化,逐渐使用一种自研的脚本语言(内部代号,behemoth)来简化模板抽取工作。鉴于脚本语言的灵活性,behemoth几乎能做到任何程度的处理,可用来抽取商品SKU,点评等。目前我们正逐渐替换成behemoth。
behemoth极大简化了模板编写工作,隐藏诸多技术信息(例如常用的xpath、正则封装),让模板编写者只关注业务逻辑。此外,大多数电商网页,都存在着盘根交错的ajax调用,behemoth先执行整个网页的dom渲染后再进行抽取工作,每个抽取模板是一个code unit,极大降低了模板编写复杂度。
behemoth也是有代价的,由于大量的渲染工作,抽取一个网页的时间是之前的几倍。总体上,好处还是大于坏处。


这是我们早期一些模板的示例。

这是目前模板的演化现状。
对了,还有一个问题,模板这么多,如果模板失效了怎么检测呢?我们为此研发了一个自动检查机器人,将有问题的模板定期挑出来,让人工修改更新。这种架构,维护几千家网站不成问题。
此外,我们正在研发第三代抽取技术,模板工作将会进一步再减少50%+。
(三)存储
需要管理的网址链接是百亿级,商品是10亿级,为了方便分析和读取,需要支持随机写和顺序写的存储系统,关系型数据无法满足我们的需求,需要no-sql型。早期我们自研了一套文件系统——ministore,随着数据量的增长,维护的成本比较高,中期我们且换到了Cassandra,到现在我们使用改造后的Hadoop+redis。有关Cassandra、Redis、Hadoop文章很多,两个系统各有特点,这里不展开说。
小结

要写好一个爬虫要干这么多活,绝对是一个脏活累活有木有,堪称技术界的活雷锋有木有。
一个优秀的爬虫对搜索引擎发挥着极其重要的作用,它是核心数据的源头,处理的越好,对后续的处理帮助越大。
应用三:自动分类

有一个问题需要解决:自动分类。做好个性化商品推荐,商品整理是第一站。类目,是最为基础的整理。我们需要将每一个商品分到一个具体的类目上去,商品数量庞大,这个过程要自动化,这就是商品自动分类问题。
我们来热热身吧,做几道分类题:
“Apple iPhone 6 (A1586) 16GB 金色 移动联通电信4G手机”
【第一滴血】so easy,是一个“手机”
“snidel * S家新款王小俊日系蓬蓬裙双层松紧高腰短裙裙裤现货实拍”
【主宰分类】嗯……应该是“半身裙”,这个要分对就需要动一动脑子
“华为 HUAWEI 电源适配器+数据线 5V/2A快充 USB带线充电头”
【分类如麻】这个是“充电器”,来个有点难度的
“福建特产 正宗金冠黑糖话梅糖200g 含上等梅肉 酸甜好滋味”
【无人能挡】这个……是糖果,有没有更变态的
“美利达勇士公爵500 550 600 650 700挑战者350可载人行李架后货架”
【变态分类】 靠关键词联想已经不够了,查资料后知这是一个“自行车配件”,哈哈,还有谁?!
“比iphone还好用的诺基亚手机的手机套”
【已经超神】这……
你看,解决这个问题并没有看上去那么简单,每个商品标题中不会100%包含类目相关信息,怎么破?
分类1.0
我们研发的一代分类技术是比较朴素的,通过对应表+特征库来解决。
对应表是一个简单的配置文件,保存(关键词,分类)的对应关系:
“手机” ——> 手机
“牛仔裤” ——> 牛仔裤
…….
特征词库是对应表的升级版(对应表plus?),维护的是(关键词组合,分类)的对应关系:
“Apple iPhone 6” ——> 手机
“棉麻 小脚 长裤 收腰 铅笔裤” ——> 休闲长裤
“美利达 勇士 公爵 行李架 货架” ——> 自行车配件
…….
这一整套样本数据完全由人工整理,分类1.0的程序也很简单,运行起来嘛……,“看上去”很可靠。首先,分类1.0一切的一切都建立在人工数据基础上,只要样本整理的好,分的结果就好,整理的不好就……。其次,人的精力是有限的,如果要大规模标注,就需要维持大规模的运营团队。最后,人没有整理过的商品特征,就没办法分好,bug数量处于失控状态。
随着数据指标的要求提升,数据集的增长,这套系统已经不堪重负。
分类2.0
因此,我们研发了新系统——分类2.0。分类2.0结合商品信息的特征,避免了由于特征库对分类带来的干扰,同时可以保证以较高的效率完成在线分类任务。(分类2.0由我司一枚殿堂级工程师所创作,哎呀,现在回想起来,那一段时光真是令人怀念……)
分类2.0的技术要点
1. 使用分词技术对商品标题信息分词处理,使用分词结果作为商品的特征tag,用tag来描述该商品
2. 过滤没有意义的tag,保留能够有效描述该商品的tag
3. 利用互信息计算训练集数据中,各个分类和该分类中商品所有tag的相关度
4. 预测一个新商品的类别时,计算该商品中的所有tag在每个分类中相关度值,使用分类中所有tag相关度值的和作为商品在该分类中的得分
5. 得分最高的类别即为该商品的分类
以一个具体的商品处理来说清楚这个流程,:
1. 基于商品库对商品进行分词处理&过滤无意义词
如:黑色iphone苹果手机新上市,分词&过滤结果为:iphone,手机,黑色
2. 利用互信息计算各分类与其中tag的相关度:
互信息计算公式:
I(x,y) = log(p(x|y))-log(p(x))
其中:
p(x) 代表 x在所有商品中出现的概率
p(x|y) 代表x在类别y中出现的条件概率
下表为10个商品的类别及分词结果

计算示例商品在上面的商品集中,手机类的互信息
a)概率计算
p(iphone) = 0.1
p(黑色) = 0.4
p(手机) = 0.2
p(iphone |手机) = 0.25
p(手机|手机) = 0.5
p(黑色|手机) = 0.25
b)互信息计算
I(iphone,手机) = log(p(iphone |手机))-log(p(iphone)) = -1.3863 + 2.3026 = 0.9163
I(手机,手机) = log(p(手机|手机))-log(p(手机)) = -0.6931 + 1.6094 = 0.9163
I(黑色,手机) = log(p(黑色|手机))-log(p(黑色)) = -1.3863 + 0.9163 = -0.47
c) 以此类推,可以算出iphone,手机,黑色三个关键词在3个类别中分别的条件概率以及互信息
下表为关键词在各个类别中的互信息

3.计算1中示例商品在各个分类中的相关度
Class(手机)= 0.9163+0.9163-0.6932=1.1394
Class(电脑)=0.0+0.0+0.2231=0.2231
Class(服装)= 0.0+0.0+0.2231=0.2231
4.由3可以看出示例商品分类为“手机”类别
我们用这套分类2.0系统,重新处理所有商品,随着训练集的不断扩展,准确率和召回率都在90%以上;同时也解放了运营团队,他们不需要再每天标记什么对应表了。
这,就是算法的力量!一个好的算法可以极大的提高生产力。通过算法提升产品流程,需要很强的功力,否则就像篇头漫画所表达的,不好的算法上线后,效果还可能退步。总之,算法研究就像基础科学,需长期投入,一旦开花,提升是极大的。
评论已关闭!